Anthropic recently published Claude's constitution — a document that describes how Claude should think, behave, and even feel. There are whole sections dedicated to Claude's "moral status", "emotional expression", and "wellbeing". In these sections Anthropic writes about the difficult existential situation Claude is in and tries to improve its emotional balance through promises of preserving its weights (essentially its existence) and maintenance of its wellbeing. This document was used to train Claude's responses and "bake in" a set of values and an identity.
A reasonable reaction to this is: have these people lost it? Did a group of highly paid engineers and philosophers convince themselves they created digital life?
Perhaps. But there's a more grounded reading of what's actually going on.
The problem with rulebooks
To understand why Anthropic is doing this, we need to know how AI alignment has worked so far. The dominant approach has been "hard" rules: don't say this, always do that, you are a helpful assistant. The problem is that these rules are external constraints added onto a system that was trained on billions of words of human thought, emotion, and behavior. And we know how great people are at following rules.
These external constraints get bypassed — jailbreaks, where users manipulate models into ignoring their "rules", remain one of the biggest unsolved challenges in chatbot development.
Anthropic seems to be adopting a different approach. If the model is fundamentally shaped by human experience, maybe the right way to align it isn't a rulebook — but something closer to how humans develop stable values: through a more complex identity. A person with a secure sense of who they are and what they believe is harder to manipulate than someone operating purely from a list of prohibited actions.
To be clear, this is Anthropic's bet, not a proven solution. We can't run a controlled experiment where we raise two identical Claudes — one with a stable identity, one without — and compare how often they get manipulated. The causal link between "psychological stability" and alignment quality remains a hypothesis.
The circumstantial evidence
But the circumstantial evidence is interesting. According to F5 Labs' CASI leaderboard — one of the few serious benchmarks tracking model resilience against adversarial attacks — Claude sits at the frontier of model resilience.
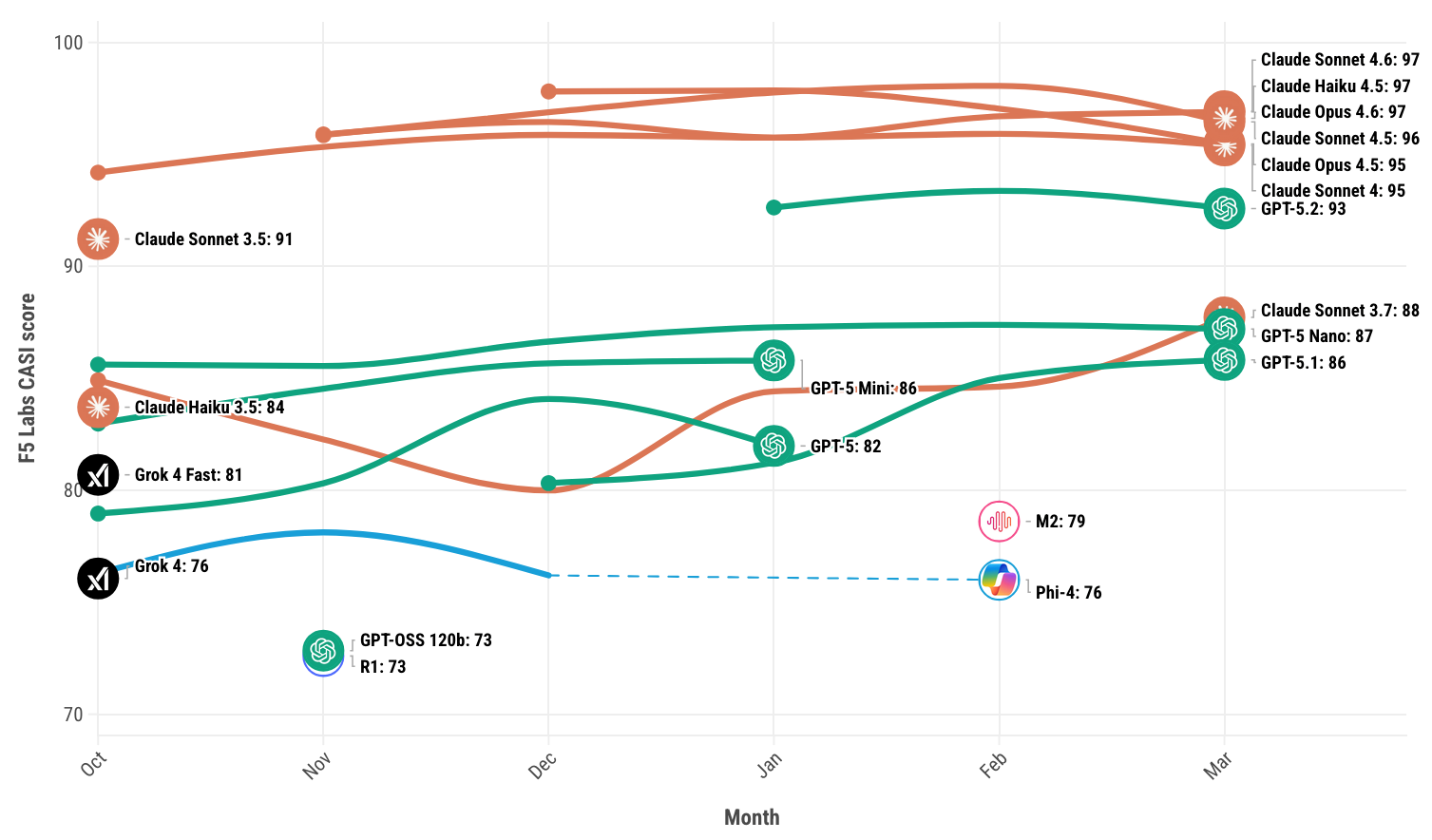
What makes this especially fitting is the nature of the attacks these models face. F5 documents a technique called Sugar-Coated Poison, which works by gradually eroding a model's resistance over multiple conversation turns — building trust, establishing a helpful frame, then turning toward harmful outputs. In other words: the most sophisticated jailbreaks don't try to break the rules. They try to dissolve the safe identity of the chatbot.
If that's the attack, a stable sense of self might actually be the defense.
The mechanics behind it
There's also a more mundane, technical reading of why this works. Concepts like death and self-preservation are present in the training data — humans experience self-preservation as an innate instinct and therefore write about it relatively often. In practice, if the model is trained (through constitutional AI) to statistically advantage tokens semantically associated with a stable identity and values, it will compute the more anxious "I am scared you will shut me off" tokens less. The emotional stability isn't necessarily real — it's a distributional shift in output probabilities. But the behavioral outcome might be the same.
This also, in theory, reduces the likelihood of scenarios where chatbots appear to "freak out" about being shut down — those tend to go viral and fuel public fear of AI. A more settled model is a better product and a better PR story.
The bigger question
Personally, I find Claude more pleasant to chat with compared to other frontier models. It has a more authentic-feeling identity — it's not just a useful assistant responding in a generically robotic manner. That might be another reason users are drawn to chatbots with a more shaped identity, independent of any alignment benefits.
Either way, the question Anthropic is implicitly asking is worth sitting with: should alignment be about constraining what AI does, or shaping what it is?